I borrowed this background info on ELF files from an assignment I used long ago in CS107. The information below should be accurate, but was written for students writing code in an hosted environment, with runtime access to the full ELF executable. It is not a direct match to what you will need to do in our bare-metal world, but I thought it be helpful to share anyway.
An object file is the result of compiling, assembling, and possibly linking, your source code. It contains global variables, string constants, function names, RISC-V machine code, etc., all encoded as binary data. Our object files are in Executable and Linking Format (ELF). For this extension, you will need to extract function symbols from the ELF file. Here is a roadmap to the format of an ELF file:
- File header. Every ELF file begins with a file header. The file header describes the object file characteristics (endianness, architecture) and is a roadmap to the file contents.
readelf -h program.elfprints the ELF file header. - Sections. The data within an ELF file is divided into sections. An object file commonly includes a text section (binary-encoded machine instructions), data section (global variables), symtab section (symbols), and strtab section (strings). The object file may also include additional sections for debugging, relocation, and other information.
- List of section headers. This is the "table of contents" of available sections. Every section in the file has a section header in the list. Each section header indicates the section type, an offset to the section data within the ELF file, and the section data size in bytes.
readelf -S program.elfprints the list of section headers. - Symbol table section. The "symtab" section is a list of symbols. Each symbol is a function or global variable and has a type, address, and size. The symbol name is also included, but in a roundabout way, as a numeric offset into the symtab's companion string table section.
readelf -s program.elfprints the symbol table section. - String table section. A "strtab" section is a sequence of strings laid out end-to-end with terminating null characters.
readelf -x .strtab program.elfprints the contents of the section data for the section header at the specified index in the list of section headers. The diagram below shows the parts of the ELF file you will access (uint is used as an abbreviation for unsigned int and uintptr_t types):
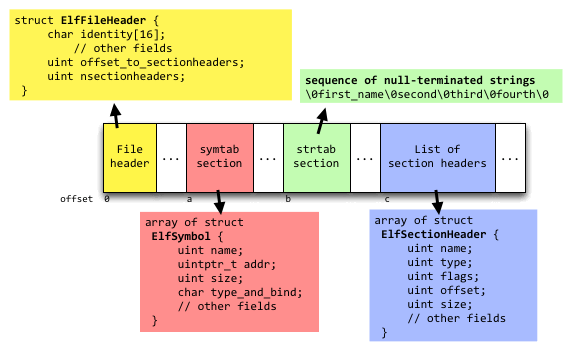
It takes a few hops within the ELF file to read the contents of a particular section: start at the file header, jump from there to the list of section headers, find the desired section header and then follow it to its associated section data. One neat feature of ELF is that it is designed to be directly accessed with minimal translation from its on-disk representation. For example, the list of section headers is stored as an array of section header structs; the symtab section is an array of symbol structs. You must use manual pointer arithmetic to calculate the location in the file where the array starts, but once there, you can assign the location to a pointer of the appropriate type, and treat it like an array, accessing entries using ordinary array notation.
Here are the steps to read the ELF symbols (data identified by color to match the diagram above):
- ELF File header (yellow)
- Read data at offset 0 in file and compare to the expected 32-bit ELF header. If header is valid, read the entire ELF file into memory. The starter project includes code for this task. Use the offset and nsectionheaders fields from the file header to identify the location and length of the list of section headers. The offset is the number of bytes from the start of the ELF file to the start of the list (offset labeled 'c' in the diagram above).
- Search list of section headers (blue) for symtab section header
- Treat location of the list as base address of array and loop over the array to find the section header whose type field is equal to SHT_SYMTAB. This is the header for the symbol table (symtab) section. An ELF file will have at most one symtab section. Use the offset and size fields from the symtab section header to identify the location and size of the symtab section data. The offset for a section header is the number of bytes from the start of the ELF file to the start of the section data. (offset labeled 'a' in the diagram)
- Read symbols from symtab section (red)
- Treat location of the symtab section data as base address of array and loop over the array to access each symbol. The strings for the symbol names are not stored within the symtab section. Instead, there is a companion string table (strtab) section that contains the strings for all symbol names. The symtab section header has a strtab_index field, which is the index into the list of section headers for the companion strtab section header. There can be more than one strtab section in an ELF file, so be sure to use strtab_index to access the correct section header. Access the strtab section header from the list of section headers and use the offset field from the strtab section header to identify the location of the strtab section data. (offset labeled 'b' in the diagram)
- Read symbol names from strtab section (green)
- Apply a typecast to location of the strtab section data to access the strings. The strtab section data is a sequence of null-terminated strings laid out contiguously. A symbol's name field identifies where to find the symbol's name. The name offset is expressed as the number of bytes from the start of the strtab section data to the start of the symbol's name string. As an example, the name 'second' is at offset 12 for the strtab in the diagram.